A few weeks ago, we (NOC’s Servers Team) faced an unsual case of performance degradation on our public cloud, ~okeanos, caused by a crippled Ceph production cluster. After a first look, there is no obvious reason why everything suddenly slowed down, and that’s where the fun begins. In this post, we’ll describe what happened and if it really was Ceph’s fault or not.
Introduction
A developer noticed that on our ~okeanos deployment in Knossos, some write requests originating from Ganeti cluster hosts (which host our VMs) to our local Ceph cluster took a lot of time. “A lot of time” means that approximately, 1 of 10 rados put operations took at least 10 seconds, instead of some milliseconds. This is a huge delay which affects greatly VM performance; for instance, a VM creation took almost 10 minutes instead of 45 seconds. Unfortunately, our monitoring system did not monitor at that time Ceph’s client-side I/O latency, which made even more difficult for use to catch this problem. It’s also worth to notice that neither we (the operations team) nor our networking team, did not receive any alerts regarding Ceph, Ganeti or anything else related on this datacenter and deployment the last days, which we could correlate to these “symptoms”.
Defining The Problem
It was not easy for us to detect the actual problem. Is it a Ceph issue? Was it a VM host issue or a network issue? Our only sign of a problem was a simple bash loop:
# dd if=/dev/urandom of=testobject bs=4M count=1
# for i in `seq 1 50`; do /usr/bin/time -f %E rados --id rbd -p rbd put testobject testobject 2>&1 | grep -v 0:00; done
0:06.37
0:09.12
0:10.44
0:08.02
0:11.01
0:07.29
Our first, obvious, target was Ceph. For the record, this cluster is running on Ceph Luminous v12.2.4, on 16 hosts with Filestore OSDs.
First of all, we checked Ceph for the following:
- Reported slow requests
- Crashed or down OSDs
- “Strange” OSD logs
- Current and history health status
- Spikes or outliers on our metrics
We did not notice anything unusual. So, we targeted our Ceph hardware nodes:
- dmesg. Anything unusual and I/O related?
- System metrics. Do we have increased I/O latency or load anywhere? Any strange spike?
- Did anything change the last days on our cluster? A change in Puppet? A kernel upgrade?
- Hardware issues? NIC error counters? Disk failures? I/O errors?
Unfortunately, we also did not observe anything unusual here; everything was working as intended and there was no sign of a problem.
At this point, we started thinking that it could be a networking problem.
Checking The Network
Because our VM hosts have an MTU of 9000, and because we have observed issues with that in the past, we tried to perform write operations with a smaller block size. With an object size of 4k, we did not observe any latency issues. So, we stopped debugging with Ceph tools and we focused on the network.
From a random VM host (let’s call it ok13-0701), we performed the following ping tests targeting all Ceph nodes at the time.
IPv4 ping with default payload size to all Ceph nodes
We observed constant packet loss only to two Ceph nodes:
rd1-0527 1000 packets transmitted, 998 received, 0% packet loss, time 103ms
rd1-0530 1000 packets transmitted, 995 received, 0% packet loss, time 157ms
IPv6 ping with default payload size to all Ceph nodes
We did not observe any packet loss.
IPv4 ping with maximum MTU set to all Ceph nodes
As before, we observed constant packet loss to the same nodes. This time, the loss percentage is much higher: ~20%:
rd1-0527 1000 packets transmitted, 775 received, 22% packet loss, time 3615ms
rd1-0530 1000 packets transmitted, 784 received, 21% packet loss, time 3466ms
When disabling the DF bit, packet loss falls to approximately 13%.
IPv6 ping with maximum MTU to all Ceph nodes
We did not observe any packet loss.
IPv4 ping with increasing MTU to all Ceph nodes
We observed packet loss to the same nodes, which was increasing proportionally with the MTU size.
Having these results, we focused our effort on checking if something is wrong on these two nodes or the leaf switches that they connect to. After some investigation, we did not find anything useful. Needless to say, we did not have any explanation on what could go wrong and why is that happening only with IPv4 traffic. So, our last resort (or at least, that’s what we thought) was to intercept traffic at all points in our network, starting from Linux hosts.
Again, we performed IPv4 ping checks with maximum MTU. Using tcpdump on bond interfaces of both hosts and traffic analyzers on the uplinks leaf switches of these hosts, we observed the following:
- ok13-0701 sends normally all ICMP echo requests
- rd1-05{27,30} receive all ICMP echo requests
- Both hosts send ICMP echo replies
- ICMP echo replies from both hosts are received from leaf switches
- ICMP echo replies do not appear on ok13-0701’s uplinks
This is an interesting result, because it indicates a problem somewhere “higher” in the network and not on our Linux hosts or their NICs or in cabling.
At this point, we still don’t have a good definition of our problem; we only know that packet loss occurs when packets travel from only one given VM host to two Ceph nodes. What would happen if we repeat all tests from a different VM host?
We repeated all ping checks from all VM hosts, between Ceph nodes (that live on the same VLAN and connect to the same leaf switches, meaning that no traffic will ever reach spines) and from a node from a different datacenter. The results were impressive:
- Each source node has IPv4 packet loss to different Ceph nodes. The average number of Ceph nodes with packet loss was 2.
- The same behavior is also observed with IPv6, in contrast with our initial hypothesis. On average, we observed packet loss from each VM host to two Ceph nodes.
- No packet loss is observed when pinging Ceph nodes between them, on the same vlan.
- All behavior is consistent. Each source node has packet loss only to certain destination nodes, which remain the same.
- No packet loss is observed when pinging Ceph nodes from other datacenters.
- We tried to perform ping checks between Ganeti clusters on different VLANs on the same DC. No packet loss was observed.
- We tried to perform ping checks from Ganeti clusters to a different DC with MTU 9000. No packet loss was observed.
- We tried to perform ping checks from our Ceph cluster to a different DC with MTU 9000. Same packet loss was observed.
Here, it would be useful to describe the architecture of our network, in order to understand traffic flows between VM and Ceph hosts. Knowing the underlying network infrastructure, can help us a lot in such debugging scenarios.
Go With The Flow
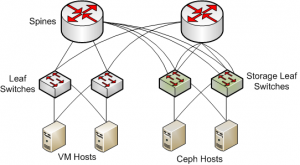
As we can see on the diagram above, each VM host is connected to two leaf switches. Each leaf switch has two uplink connections to the datacenter’s spines. On the other side, each Ceph host also has two connections to each leaf switch. All Ceph nodes are connected to the same leaf switches, which are more powerful than VM host leaf switches. Each of those leaf switches has four uplinks to each spine, instead of two of the other leaves. All links between spines and leaf switches are optical ones. There can be multiple paths for each flow inside the datacenter. Let’s check all possible paths for a echo request generated from a VM host, targeting a Ceph node.
- Operator issues an ICMP echo request from the VM host to a Ceph node. Both nodes live on different VLANs, thus the VM host generates an ethernet frame with destination MAC address, the address of the IRB interface of the current VLAN.
- All hosts have both NICs bonded together in layer3+4 hashing mode. Thus, the kernel decides from which NIC to send the frame based on source and destination IP and ports. There are two possible links from where the frame can flow through.
- The frame arrives at a leaf switch. It will forward the frame based on target VLAN. All Ceph nodes live on the same VLAN, which means that all traffic from VM hosts targeting Ceph nodes will always pass through the same leaf-spine uplinks.
- After the spine receives the frame, it removes its ethernet frame and, decides where to forward it. After making the decision, it will forward it to one Ceph leaf switch. Each spine has four links with each Ceph leaf switch and load will be balanced using a layer3+4 hashing algorithm.
- A leaf switch receives the frame and forwards it to the appropriate Ceph node. Each leaf has one connection to each node.
Having described the traffic flows inside our datacenter, we can conclude for each traffic flow, there are 8 different paths that an IP packet can follow. Also, as stated above, our Ceph cluster consists of 16 nodes and we observe packet loss from each VM host to 2 Ceph nodes on average. This can not be a coincidence…
A Dysfunctional…
After a discussion with our network team, we started to look for more subtle issues on network ports and cables on links between spines and leaves that may not be reported by our monitoring systems. After double-checking all possibly affected interfaces and devices for errors and logs, our network team decided to perform dedicated ping checks between all affected spine-leaf point-to-point links. If packet loss occurs only on certain links, we can disable them and repeat our initial checks from VM hosts to see if the behavior persists. If yes, we have to look somewhere else. If not, it means that we hit a hardware error that’s not reported by vendor-exclusive monitoring tools. Fortunately, after checking all uplinks, we observed 20% packet loss at one link between one spine and one Ceph leaf switch. After disabling this link, we repeated our checks from VM hosts and noticed that the packet loss was gone, together with all delays observed when performing RADOS operations.
Our network team, with the assistance of our datacenter technicians found the real issue: a problematic QSFP on the aforementioned link. Unfortunately, the network device did not report anything anywhere, even on low-level diagnostic commands. After replacing the problematic QSFP, we started sending traffic over this link and everything looked fine: the packet loss was gone and no performance degradation was anymore observed on RADOS operations.
And Now What?
This journey took approximately three days, involving people from two different teams. Of course, such issues affect immediatly our services and must be detected and mitigated as soon as possible. In order to detect these problems, our network team introduced health checks which perform pings between uplinks in our data centers in an automated way and report back any unusual findings. Furthermore, we are in the process of writing metric-based health checks that will monitor read and write operations on our Ceph clusters and report back any anomalies. On a side note, our strategy on monitoring the network’s uplinks will be covered in an upcoming post by our network team.
Monitoring plays a vital role when operating and debugging complex systems, especially when they consist of multiple moving parts and are designed from scratch by your organization and not by a third party. It is vital for us to have insight on all parts of our infrastructure, in order to improve communication between teams, debug problems more efficiently and provide reliable services to the Greek academic community.
Finally, we would also like to thank Lefteris Poulakakis (lepou_at_noc_grnet_(gr)) from the Network Team, who assisted us during this whole debugging journey and played a vital role in debugging and fixing this issue.